안녕하세요, 조교입니다.
지난 시간들에 걸쳐서 NLL, FID, IS를 살펴보았습니다.
간단히 정리하자면,
1. NLL은 학습한 모델이 Density 관점에서 얼마나 true data 근처에 몰려있는지 측정하는 것이고,
2. FID는 학습한 모델에서 뽑아낸 데이터가 얼마나 true data 근처에 몰려있는지 측정하는 것이며,
3) IS는 학습한 모델에서 뽑아낸 데이터가 얼마나 잘 classify되는가를 측정하는 것입니다.
오늘은 Improved Precision & Improved Recall에 대해 설명드리겠습니다.
Precision 및 recall은 classification problem에서는 익숙하고 직관적인 metric들이지만,
generation problem에서는 기존의 정의를 그대로 사용하기 어렵습니다.
왜냐하면 False Positive, False Negative 등의 개념이 존재하지 않기 때문입니다.
그렇기 때문에 Generative model에서는 아래와 같이 개념을 정립하였습니다.
precision: 샘플링한 이미지가 얼마나 그럴듯한지
recall: 샘플링한 이미지가 얼마나 다양한지
위와 같은 개념을 기준으로 정확한 정의를 아래에서 설명하겠습니다.
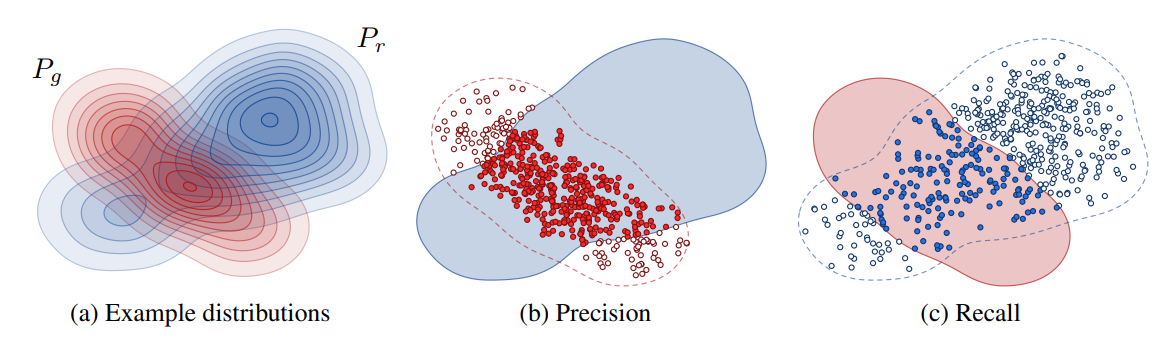
위 그림이 precision과 recall에 대한 다른 직관을 설명하고 있습니다.
precision은 생성된 이미지가 얼마나 data distribution에 포함되는지 그 비율을 나타내는데요,
생성된 이미지를 model이 True로 classify한 것이라 생각하고
data distribution은 실제로 True라고 생각한다면,
precision은 True Positive (생성된 이미지가 얼마나 그럴듯한지) / (True Positive + False Positive (생성된 이미지 중 그럴싸하지 않는 이미지들)) 라고 비유적으로 생각할 수 있습니다.
마찬가지로, recall 또한 전체 데이터셋에서 generative distribution에 포함되는 데이터의 비율이니,
True Positive / (True Positive + False Negative (주어진 데이터셋에서 생성 분포에 속하지 않는 데이터)) 라고 생각할 수 있습니다.
수식으로 살펴보면, f(\phi,\Phi)=\bigg\{\begin{array}{ll}1,&\text{if }\Vert\phi-\phi'\Vert_{2}\le\Vert\phi'-NN_k(\phi',\Phi)\Vert_{2}\text{ for at least one }\phi'\in\Phi\\ 0,&\text{otherwise} \end{array}f(ϕ,Φ)={1,0,if ∥ϕ−ϕ′∥2≤∥ϕ′−NNk(ϕ′,Φ)∥2 for at least one ϕ′∈Φotherwise라고 하겠습니다. 여기서 NN_k(\phi',\Phi)NNk(ϕ′,Φ) 는 set \PhiΦ 들 중에 \phi'ϕ′ 과 Euclidean distance로 k번째로 가까운 feature \phiϕ 를 의미합니다, 즉 NN은 Neural Network의 약자가 아니라, Nearest Neighborhood의 약자입니다.
위 수식은 그 자체로 이해될 수 있는 것이 아니라 아래처럼 쓰인 용례에서 이해될 수 있는 것인데요, 그 이해를 위해 precision과 recall을 수학적으로 정의하자면,
precision(\Phi_{r},\Phi_{g})=\frac{1}{\vert\Phi_{g}\vert}\sum_{\phi_{g}\in\Phi_{g}}f(\phi_{g},\Phi_{r})precision(Φr,Φg)=∣Φg∣1∑ϕg∈Φgf(ϕg,Φr) 이며, recall(\Phi_{r},\Phi_{g})=\frac{1}{\vert\Phi_{r}\vert}\sum_{\phi_{r}\in\Phi_{r}}f(\phi_{r},\Phi_{g})recall(Φr,Φg)=∣Φr∣1∑ϕr∈Φrf(ϕr,Φg) 가 됩니다.
여기서, f(\phi_{g},\Phi_{r})f(ϕg,Φr) 은 fake data인 \phi_{g}ϕg 가 우리에게 주어진 실제 데이터들 중 어떤 데이터 instance라도 상관 없으니, 그 instance의 k-th nearest neighborhood 안에만 들어가면 1을, 그렇지 않으면 0을 output으로 갖습니다. 그렇지 않다는 것은, 어떤 데이터 instance라도 그 k-th nearest neighbhorhood 안에 \phi_{g}ϕg 가 포함되지 않는다는 것입니다. f(\phi_{g},\Phi_{r})f(ϕg,Φr) 가 1의 값을 가진다면 그 데이터 \phi_{g}ϕg 는 실제로 realistic한 데이터라고 생각할 수 있습니다. 여기서 data의 feature인 \phiϕ 는 논문에서는 VGG-16 network를 사용했으나, 다른 논문들에서는 Inception network 등도 사용하는 추세에 있습니다. recall의 경우도 마찬가지로, f(\phi_{r},\Phi_{g})f(ϕr,Φg) 는 \phi_{r}ϕr 이 fake dataset에서 적당히 가까운 위치에 있는지를 측정해, 가깝게 있다면 1, 멀리 있다면 0을 내뱉는 함수입니다.
위와 같이 Improved Precision & Improved Recall에 대하여 알아보았습니다.
다음 시간에는 최근에 FID의 보완점을 갖고 있는 sFID measure에 대해 설명드리겠습니다.
comment